
EMI | Datavisualisation
 Echanges de mails, achats, livres,
position géographique, statistiques… Tout ce qui est enregistré peut constituer une
donnée.
Echanges de mails, achats, livres,
position géographique, statistiques… Tout ce qui est enregistré peut constituer une
donnée.
La datavisualisation ou dataviz est une technique de représentation de ces données par la création de graphiques dont le design aide à la compréhension et à l’analyse d’une problématique précise.
Loin d'une simple infographie, la dataviz est de plus en plus souvent interactive, actualisée en permanence et sa fonction est d'abord de faire sens. Secteur en nette progression, elle répond à la fois aux demandes des entreprises et des médias.
Voir aussi
Voir aussi
 cartographie
cartographie biais
biais algorithme
algorithme datajournalisme
datajournalisme

 DYS
DYS
 NO-DYS
NO-DYS
De quoi s’agit-il ?
Petite histoire de la datavisualisation
L’homme classe et quantifie des informations sous forme de tableaux depuis des siècles. Leur représentation visuelle, elle aussi est ancienne et, en ce sens, la datavisualisation n'est pas réellement nouvelle.
Au Xee siècle, un manuscrit du Commentaire au Songe de Scipion de Cicéron présente la "description du mouvement des planètes au cours du temps". Elle donne à voir différents niveaux d'élévation des astres dans le ciel au cours de la journée. On a donc, sur le même plan, des informations à la fois spatiales et temporelles.
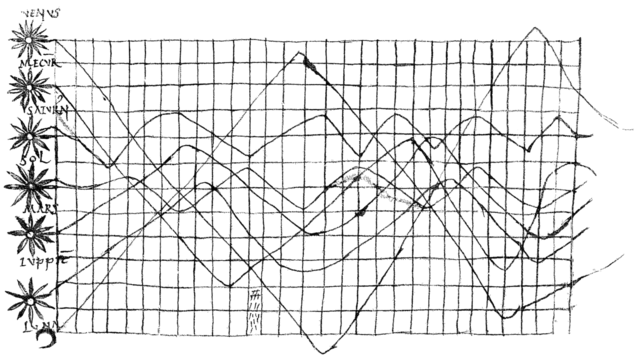
publié dans un manuscrit du xe siècle de Macrobe.
Crédits : Wikimedia Commons
En 1869 Charles Joseph Minard (1781-1870), super-intendant de l'École des ponts et chaussées, illustre les pertes lors de la campagne napoléonienne de Russie.

John Snow
La carte de l'épidémie de choléra de John Snow (pas celui de Game of Thrones !) est une des
premières
cartes de points. Elle utilise des petites barres accolées aux blocs d'immeubles pour indiquer
le
nombre
de morts dues au choléra pour chaque foyer de ce quartier de Londres. La concentration et la
longueur de
ces barres mettent en évidence certains blocs d'immeubles, ce qui permet de s'interroger sur les
raisons
d'une telle tendance, par rapport aux autres immeubles.
Résultat : cette carte a permis de déterminer que les foyers qui ont le plus
été
touchés par le choléra utilisaient tous de l'eau provenant de la même pompe.
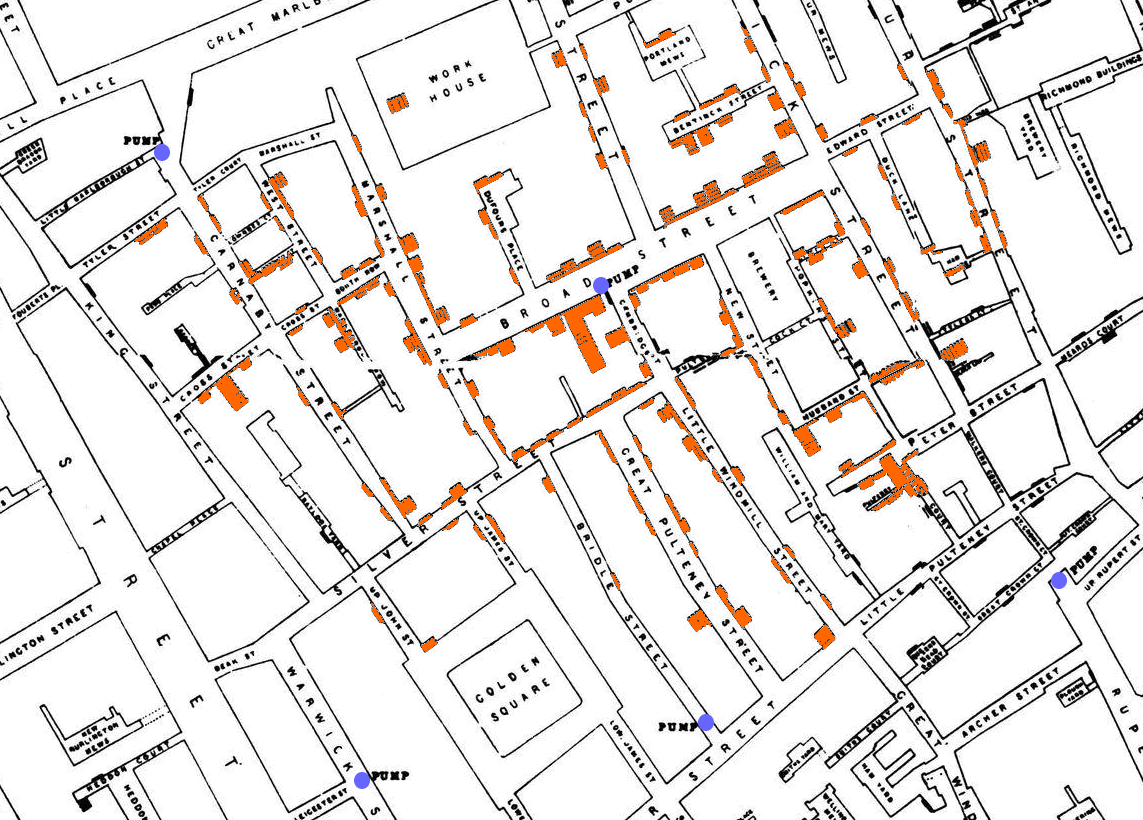
John Snow - L'épidémiologie
Je ne sais pas si au final les marcheurs blancs de Game of Thrones feront plus de morts
que le
choléra
mais dans les deux cas un Snow aura essayé de les stopper !
La petite histoire d'un des pères de l'épidémiologie.

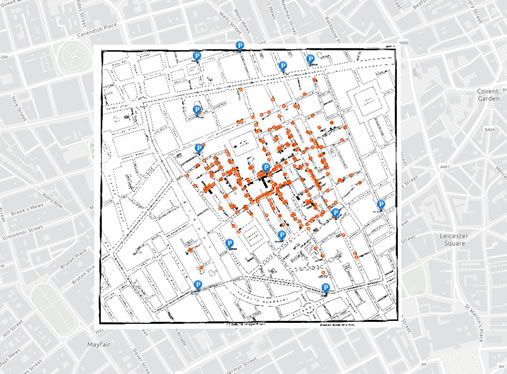 Un tutoriel en ligne propose le fond de
cartes
et
les données de l'épidémie de choléra de 1854.
Un tutoriel en ligne propose le fond de
cartes
et
les données de l'épidémie de choléra de 1854.
Tout est modifiable, et chacun pourra
raconter
ou
visualiser sa propre interprétation des données.
"Un SIG (système d’informations géographiques) vous permet de comparer et d’analyser des données géographiques pour trouver des modèles. En 1854, le terme SIG n’existait pas, mais la carte des décès dus au choléra de John Snow lui a permis de poser des questions et de résoudre des problèmes, tout comme nous le faisons aujourd’hui avec les SIG.
Dans cette leçon, vous allez cartographier à nouveau les données de John Snow dans ArcGIS Online, avec cependant des méthodes auxquelles il n’avait pas accès à l’époque. De plus, vous partagerez votre travail dans une simple story map."
 learn.arcgis.com
learn.arcgis.com
La Dataviz moderne a vraiment commencé à se développer au XXème siècle, notamment avec Internet : la collecte de données est simplifiée, leur accès est possible en continu, de nouveaux outils de visualisation sont élaborés.
Comment, pourquoi ?
L’objectif de la datavisualisation est de :
- Faire parler des données brutes
- Synthétiser les enjeux essentiels d’un set de données
- Traduire visuellement des données
« La datavisualisation doit retenir l’intérêt de ses interlocuteurs, à travers une histoire. Elle doit enrichir leur culture commune sur un thème caractérisé et identifiable. Elle a pour finalité de convaincre ses interlocuteurs, de les inviter à agir, de les éclairer, d’enrichir leurs connaissances ou de les inviter à se remettre en question sur une vision de la réalité grâce à des données rationnelles et objectives. »source : Alice de Bailliencourt
Naissance d'un cerveau. L'expo neuro ludique
Martin, dessinateur scientifique et futur papa, tient le carnet de bord du développement de son bébé. Le journal débute lorsque la peau et le cerveau commencent leur formation à partir d'un même feuillet de cellules et se poursuit jusqu'à la naissance de Lucie, voire après, puisque l'histoire du cerveau ne s'arrête pas là !
Datas ?
 Elle
peut être ouverte, sensible, aberrante,
personnelle, publique, statistique, numérique, de référence, cachée, forfaitaire… Elle est
stockée
ailleurs dans des usines des Data center mais présente partout.
Elle
peut être ouverte, sensible, aberrante,
personnelle, publique, statistique, numérique, de référence, cachée, forfaitaire… Elle est
stockée
ailleurs dans des usines des Data center mais présente partout.
Réactualisée en permanence, voire rafraîchie en temps réel, elle a à la fois le don
d'ubiquité
et
d'immortalité (quoi que …) et ne se périme pas.
C'est la matière première du data journaliste.
Tout ce qui est enregistré peut constituer une donnée. Vos échanges de mails, le web, vos achats, les livres, votre position géographique les statistiques… tout est donnée numérique.
Evidemment, les services marketing, les banques et les assurances sont les premiers à s'intéresser à ces données. En effet différentes méthodes d'analyse vont permettre d'en extraire des informations très utiles.
Mais d'autres sciences peuvent aussi s'y intéresser. Cela va de la médecine à l'ingénierie électrique en passant par la génétique ou l'aérospatiale.
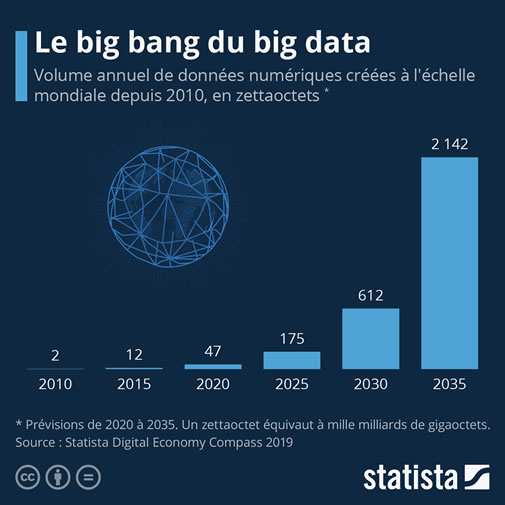 Avec le « Big Data
déf.
»
c'est
l'explosion quantitative de la donnée numérique, notamment lorsqu'elle est ouverte et à la
disposition
via l'Open data.
module
Avec le « Big Data
déf.
»
c'est
l'explosion quantitative de la donnée numérique, notamment lorsqu'elle est ouverte et à la
disposition
via l'Open data.
module
Elle est en croissance continuelle, et le problème est de plus en plus souvent non pas d'avoir la possibilité d'y accéder mais de la trouver.
Chaque jour, nous générons ainsi 2,5 trillions d’octets de données et c’est ça qu’on appelle le « Big Data ».
Cet obscur terme anglais désigne simplement le flux permanent de toutes ces données informatiques, qui circulent à travers le monde, à chaque instant. Un flux auquel chacun d’entre nous participe activement.
Et ce sont des algorithmes qui se chargent de les traiter pour les rendre utiles.
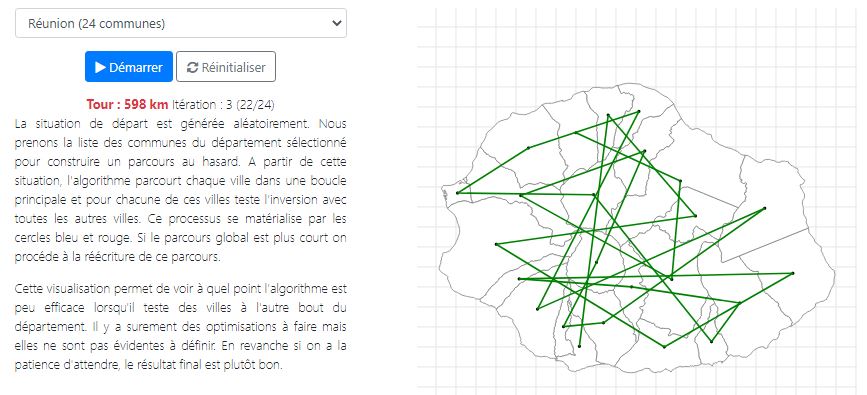
Le voyageur de commerce
Ce site permet de sélectionnez une commune de France et de lancer une modélisation pour calculer le chemin le plus court.
Big data
Le big data - 60 secondes pour comprendre
Que sont précisément ces données ? Comment sont-elles générées ? A quoi servent-elles concrètement ?
Ouverte ?
 Une
donnée ouverte (open
data) est une donnée numérique d'origine publique ou privée. Elle peut être notamment produite
par
une collectivité ou un service public (éventuellement délégué) ou une entreprise.
Une
donnée ouverte (open
data) est une donnée numérique d'origine publique ou privée. Elle peut être notamment produite
par
une collectivité ou un service public (éventuellement délégué) ou une entreprise.
Elle est diffusée de manière structurée selon une méthodologie et une licence libre
garantissant son libre accès et sa réutilisation par tous, sans restriction technique, juridique
ou
financière.
L'ouverture des données (en anglais open data) représente à la fois un mouvement, une philosophie d'accès à l'information et une pratique de publication de données librement accessibles et exploitables.
Elle s'inscrit dans une tendance qui considère l'information publique comme un bien commun dont la diffusion est d'intérêt public et général. ( Wikipédia).
 Référentiel Général
d'Interopérabilité
Référentiel Général
d'Interopérabilité
Voir par exemple Datactivist, une société coopérative et participative qui se donne pour mission d’ouvrir les données et de les rendre utiles et utilisées.
datactivist.coop/fr/
OSINT
OSINT est l'acronyme pour Open Source INTelligence, ou renseignement de sources ouvertes. C'est une discipline qui consiste à collecter des données et des informations en ligne pour faire du renseignement, le plus souvent économique.
Selon les sources de l'OSINT peuvent être divisées en six catégories différentes de flux d'informations :
- Les médias, journaux imprimés, magazines, radios, chaînes de télévision dans les différents pays
- Internet, les publications en ligne, les blogs, les groupes de discussion, les médias citoyens, YouTube et autres réseaux sociaux
- Les données gouvernementales, rapports, budgets, auditions, annuaires, conférences de presse, sites web officiels et discours. Ces informations proviennent de sources officielles, mais sont bien publiquement accessibles et peuvent être utilisées librement et gratuitement
- Les publications professionnelles et académiques, provenant de revues académiques, conférences, publications et thèses
- Les données commerciales, imagerie satellite, évaluations financières et industrielles et bases de données
- La littérature grise, rapports techniques, prépublications, brevets, documents de travail, documents commerciaux, travaux non publiés et lettres d'information
Bellingcat est un groupe international indépendant de chercheurs, d'enquêteurs et de journalistes citoyens utilisant à la fois : enquêtes 'open source' et réseaux sociaux, pour sonder une variété de sujets - trafiquants de drogue mexicains, crimes contre l'humanité, suivi de l'utilisation d'armes chimiques et conflits dans le monde entier.
 https://fr.bellingcat.com/
https://fr.bellingcat.com/
Quelques outils
Ventusky permet d'afficher la carte des données météo (températures, vents, précipitations, vent, pollution etc.) à une date et un lieux donnés.
www.ventusky.com/
Suncalc permet d'afficher l'ombre à une date et un lieux donnés.
www.suncalc.org/
Sentinel permet d'afficher uen carte satellite d'un endroit dans le monde. Nécessite un compte Payant.
apps.sentinel-hub.com/
Un fichier de favoris répartis en catégorie proposé par le site https://www.osintcombine.com/osint-bookmarks répartis en catégories (surveillance de zone et d'événement, recherche de personne, profilage d'entreprise, cartographie, intelligence Artificielle , crypto-monnaieetc.).
Une autre liste d'outils, de plus de 400 outils, présentée sous forme de tableau ou de bulles.
metaosint.github.io/
Loi pour une République numérique
 Le
premier volet de la loi pour une République numérique (dite "loi Lemaire" promulguée le 7
octobre 2016) vise à favoriser la "circulation des données et du savoir" :
Le
premier volet de la loi pour une République numérique (dite "loi Lemaire" promulguée le 7
octobre 2016) vise à favoriser la "circulation des données et du savoir" :
- ouverture des données publiques et d’intérêt général
- création d’un service public de la donnée
- libre accès aux écrits de la recherche publique
Un triple objectif :
- « Accroître la transparence des autorités publiques »
- « Améliorer les services publics »
- « Stimuler le développement de nouvelles activités économiques »
Désormais, les administrations au sens large doivent publier en ligne dans un standard ouvert leurs principaux documents, y compris leurs codes sources, ainsi que leurs bases de données et les données qui présentent un intérêt économique, social, sanitaire ou environnemental. L’ouverture des données concerne aussi les algorithmes publics.
Sont notamment concernées les données des délégations de service public (dans les transports, l’eau, la gestion des déchets, etc.), les données relatives aux subventions publiques supérieures à 23 000 euros ou encore les données de consommation d’énergie. L'ouverture des données de jurisprudence était également prévue par la loi Lemaire. Toutefois, les décrets d'application ne sont jamais parus.
Les chercheurs peuvent dorénavant mettre en ligne en libre accès (open access) les résultats de leurs travaux de recherche financés à plus de 50% par des fonds publics après une période d’embargo de six ou douze mois.
Les acteurs publics concernés sont par ailleurs tenus de mettre à jour ces fichiers « de façon régulière ».
Article L312-1-1
 les administrations
publient
en ligne
les administrations
publient
en ligne
République numérique :
qu'a changé la loi du 7
octobre
2016 ?
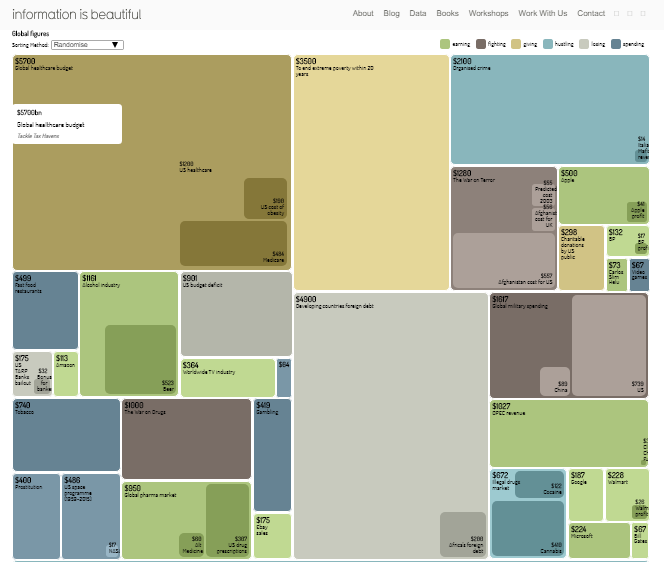
Une image vaut mille mots !?
Pourquoi ne pas se contenter de simples listes ou tableaux de données ?
Parce que, lorsqu'il s'agit de comprendre un très grand nombre d’éléments en un seul coup d’œil, les cartes ou graphiques permettent de simplifier la compréhension d'éléments complexes et de les appréhender très rapidement.
La psychologie de la forme, théorie de la Gestalt ou gestaltisme (de l'allemand, Gestaltpsychologie) est une théorie psychologique et philosophique proposée au début du xxe siècle selon laquelle les processus de la perception et de la représentation mentale traitent les phénomènes comme des formes globales plutôt que comme l'addition ou la juxtaposition d'éléments simples.
90% des informations transmises au cerveau seraient ainsi visuelles.
Les images sont traitées 60 000 fois plus rapidement que les données textuelles.
Une image vaut mille mots !? (2)
Avant/après. Combien comptez-vous de 6 ?
Système 1, système 2
 Dans le livre Les deux vitesses de la pensée Daniel Kahneman résume les recherches qu'il
a
effectuées au fil des décennies en collaboration avec Amos Tversky.
Dans le livre Les deux vitesses de la pensée Daniel Kahneman résume les recherches qu'il
a
effectuées au fil des décennies en collaboration avec Amos Tversky.
La thèse centrale du livre est la distinction entre deux modes de pensée : le système 1 (rapide, instinctif et émotionnel) et le système 2 (plus lent, plus réfléchi et plus logique).
Le livre revient ensuite sur les biais cognitifs associés à chacun de ces modes de pensée, en commençant par les recherches de Daniel Kahneman sur l'aversion à la perte. Du cadrage des choix en passant par la substitution, le livre met à profit plusieurs décennies de recherche universitaire pour montrer une trop grande confiance dans le jugement humain souvent "trommpé" par son cerveau.

Infographie VS datavis
Les deux transforment des données en visualisations faciles à comprendre.
mais

Quelles formations ? Quels métiers ?
Datajournaliste
Un data journaliste ou « journaliste de données » est certes un journaliste, mais avant tout un spécialiste, dont la fonction principale est de récolter, recouper certaines données précises qui permettront de « visualiser » au mieux l’information.
www.orientation.com/
L'école des Gobelins propose par exemple une formation Datavisualisation-Data Design.
www.gobelins.fr/
Le CNAM propose une UE « la datavisualisation pour tous » qui permet d'ouvrir les compétences de visualisation au plus grand nombre en donnant une compréhension claire et complète des possibilités offertes, et du potentiel des outils afin d'exploiter des données et de réaliser des visualisations pertinentes.
formation.cnam.fr/
Datajournalisme en milieu scolaire
Le Datajournalisme en milieu scolaire : quelles pratiques ? quelles compétences ? quelles entrées disciplinaires ? Cet article fait suite à la formation du CLEMI-DAFOR à Paris. "Le DataJournalisme en milieu scolaire, approches pour des projets innovants" (7 mai 2019).

www.ac-paris.fr/
Data scientist
Chargé de la gestion, de l'analyse et de l'exploitation des données massives au sein d'une entreprise, le Data Scientist est l'évolution du Data Analyst à l'ère du Big Data.
COMMENT DEVENIR DATA SCIENTIST ou data analyst : métier, formation, salaire et Big Data !
Maintenant j'aime le lundi
Leur mission ? Résoudre des énigmes et jouer avec d’immenses quantités d’informations. Pourquoi ? Pour tirer des tendances, établir des profils, trouver des gènes responsables d’une maladie, évaluer la culpabilité d’un accusé dans un procès, vous cibler la bonne publicité au bon moment…
www.cidj.com/metiers/
www.apec.fr/
www.letudiant.fr/
Vents et mots dans Game of throne

Ressources
Le Codex Atlanticus ou Codice Atlantico est un recueil de dessins et de notes de Léonard de Vinci.
 lien vers le site
lien vers le site
La Commission nationale de l’informatique et des libertés (CNIL) est une institution indépendante chargée de veiller au respect de l'identité humaine, de la vie privée et des libertés numériques.
Une collection d'outils permettant de visualiser et d'analyser les médias sociaux.

Base de données mondiale de la société visant à construire un catalogue de comportements et de croyances à l'échelle de la société humaine dans tous les pays.
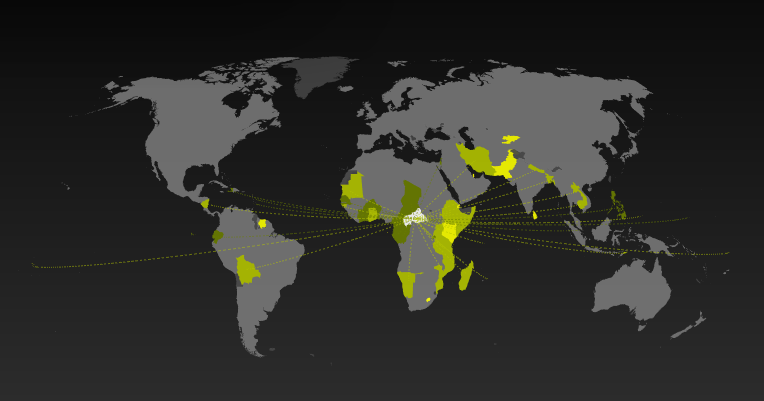
Destinations possibles à partir de… vers pour les pays du monde.
Le médialab de Science Po
Actus
Le médialab de Science Po mène des recherches thématiques et méthodologiques qui interrogent les relations entre le numérique et nos sociétés.
medialab.sciencespo.fr/
Activités pour la classe
Datasprint pédagogique
Un datasprint pédagogique est la réalisation d'une visualisation graphique, en temps limité, à partir d'un jeu de données, sur un thème donné.
Le plus souvent issue de données ouvertes, il peut aussi être produit (données brutes d'enquêtes etc.).

Quelques heures, jours ou mois, il s'agit avant tout d'aboutir dans un temps limité à établir une production graphique qui fasse émerger des informations, un angle, une données en relation avec le thème et à partir des datas.
Timeline, carte, camemberts, bulles, tout est possible et tous les outils, y compris non numériques, sont possibles.
Un exemple de la réalisation des élèves de 3e CDSG (Classe Défense et Sécurité Globale) du collège des Avaloirs de Pré-en-Pail-Saint-Samson sur le thèmes des "Les soldats de Pré-en-Pail Saint-Samson pendant la Première Guerre mondiale" sur un mois.
Le travail de la classe est publié sur le site data.gouv.fr.
lesavaloirs.lamayenne.e-lyco.fr/
Flightradar24
 Le
site www.flightradar24.com/ est très connu par tous
ceux
qui souhaitent accèder à un instantané ou aux archives des vols aériens.
Le
site www.flightradar24.com/ est très connu par tous
ceux
qui souhaitent accèder à un instantané ou aux archives des vols aériens.
Les transpondeurs des avions émettent un signal ADS-B (Automatic dependent surveillance-broadcast)
environ une fois par seconde.
Les données GPS (latitude, longitude,
altitude) ainsi que sa vitesse (y compris sa vitesse verticale), l’adresse unique de l’avion et le
numéro du vol sont ainsi transmises via un canal 1090 MHz.
Les données sont transmises sur une distance d'environ 240 km.
Elles incluent également le code de transpondeur ( » squawk « ) qui
peut parfois servir pour communiquer des informations codées (en cas d’urgence la valeur est 7700 et
en cas de détournement 7500).
 https://www.aerovfr.com/2019/12/deux-ou-trois-choses-sur-lads-b/
https://www.aerovfr.com/2019/12/deux-ou-trois-choses-sur-lads-b/
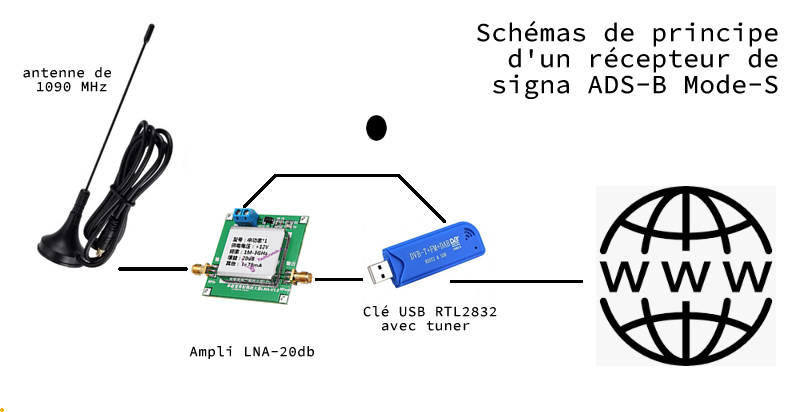 Ces données sont ensuite recueillies par des milliers de bénévoles via une antenne très simple (et
qui coute
moins d'une cinquantaine d'euros) et que l'on peut même fabriquer soi-même. Ces données sont ensuite
retransmises en données ouvertes vers Flightradar.
Ces données sont ensuite recueillies par des milliers de bénévoles via une antenne très simple (et
qui coute
moins d'une cinquantaine d'euros) et que l'on peut même fabriquer soi-même. Ces données sont ensuite
retransmises en données ouvertes vers Flightradar.
Les données une fois agrégées, et augmentées d'informations diverses sur les avions (photos, informations etc.) servent alors à établir la carte des vols en quasi direct.
Pratiquement tous les appareils sont ainsi tracés, avions militaires, jets privés etc. et cela pour d'évidentes raison de sécurité. Un avion de chasse, quand il n'est pas en opération doit s'insérer dans le trafic normal, avec une vitesse et un vol compatible avec les trajectoires des autres aéronefs.
Même les drones de loisir civils disposent désormais d'un transpondeur à partir d'un certain poids.
Voir également du même style globe.adsbexchange.com/.
adsb.exposed
Dans le même esprit ADSB permet d'agréger des millions de déplacements ou de vols par type d'engins sur une même carte en fonction de critères du type Aibus VS Boeing, type d'avions, déplacements d'Elon Musk ou, comme ici, des vols militaires.
 https://adsb.exposed/
https://adsb.exposed/
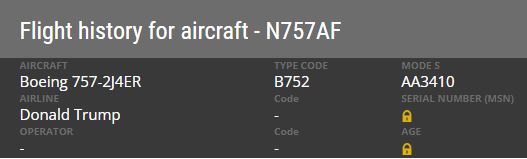
L'article 20 de la Convention de Chicago indique que tout aéronef engagé dans le trafic international doit porter des marques de nationalité et d'immatriculation. Ces règles d'immatriculations sont définies par l'OACI (Organisation de l'Aviation Civile Internationale). Les numéros d’immatriculation des aéronefs débutent par un code à un ou deux chiffres. Ce code est aussi celui du pays d’immatriculation.
Dans quel pays est immatriculé LX-N90451 ?
A qui appartient N-757AF ?
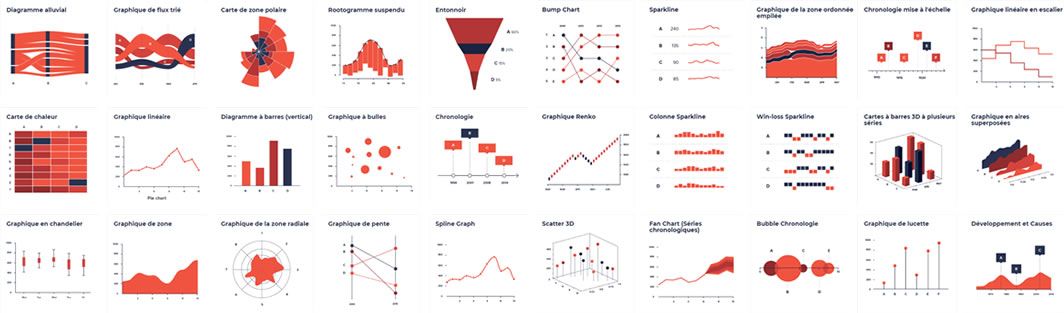
Visualisations
Temporelle, les tendancess
La visualisation temporelle, comme son nom l'indique, repose sur une échelle de temps. C'est une représentation très intuitive qui permet d’avoir un rapide aperçu et général sur un évolution d'un temps donné. Elle peut être utilisée comme un outil d’exploration au sein de secs temporelles.
Les variations temporelles sont la base de votre histoire. Pourquoi y a t-il tel ou tel pic ? Pourquoi y a t-il telle ou telle chute ? L’intérêt est de mettre en évidence les parties intéressantes de la représentation pour les destinataires.
Autres exemples
Des proportions / comparaison
Les données relatives aux proportions sont regroupées par catégories et sous-catégories. La distribution globale, les maxima-minima, les proportions sont autant d'informations qui permettent de se faire une idée.

Des concepts
Les données sont représentées sous forme conceptuelles.
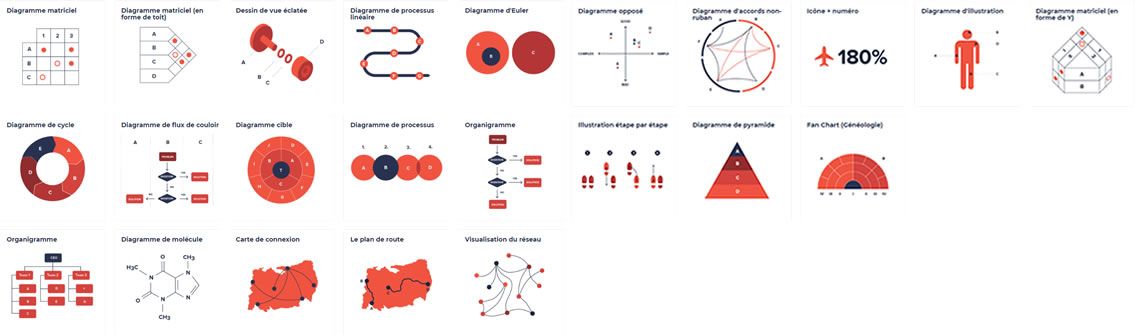
Des corrélations

De la distribution

Géographiques
Les données relatives aux proportions sont regroupées par catégories et sous-catégories. La distribution globale, les maxima-minimas, les proportions sont autant d'information qui permettent de se faire une idée.
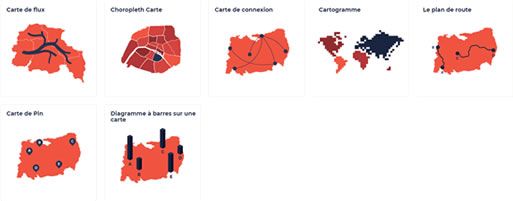
Des parties d'un tout
Graphique interactif
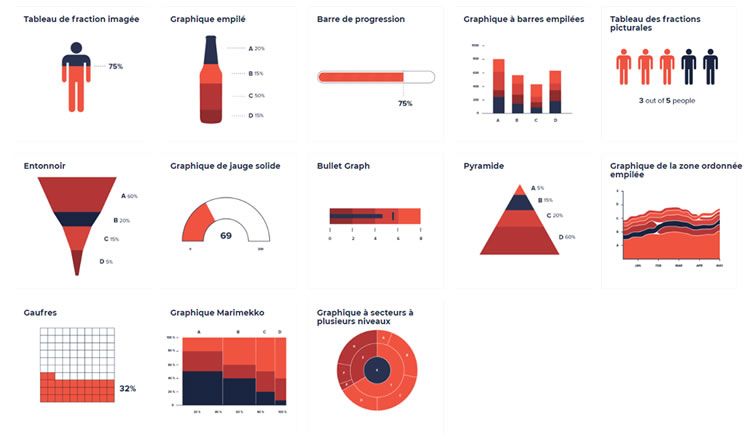
Choisir une visualisation
DatavisCatalogue est un catalogue de visualisation de données qui vous permet choisir un type de graphique et en afficher une vue et une description.

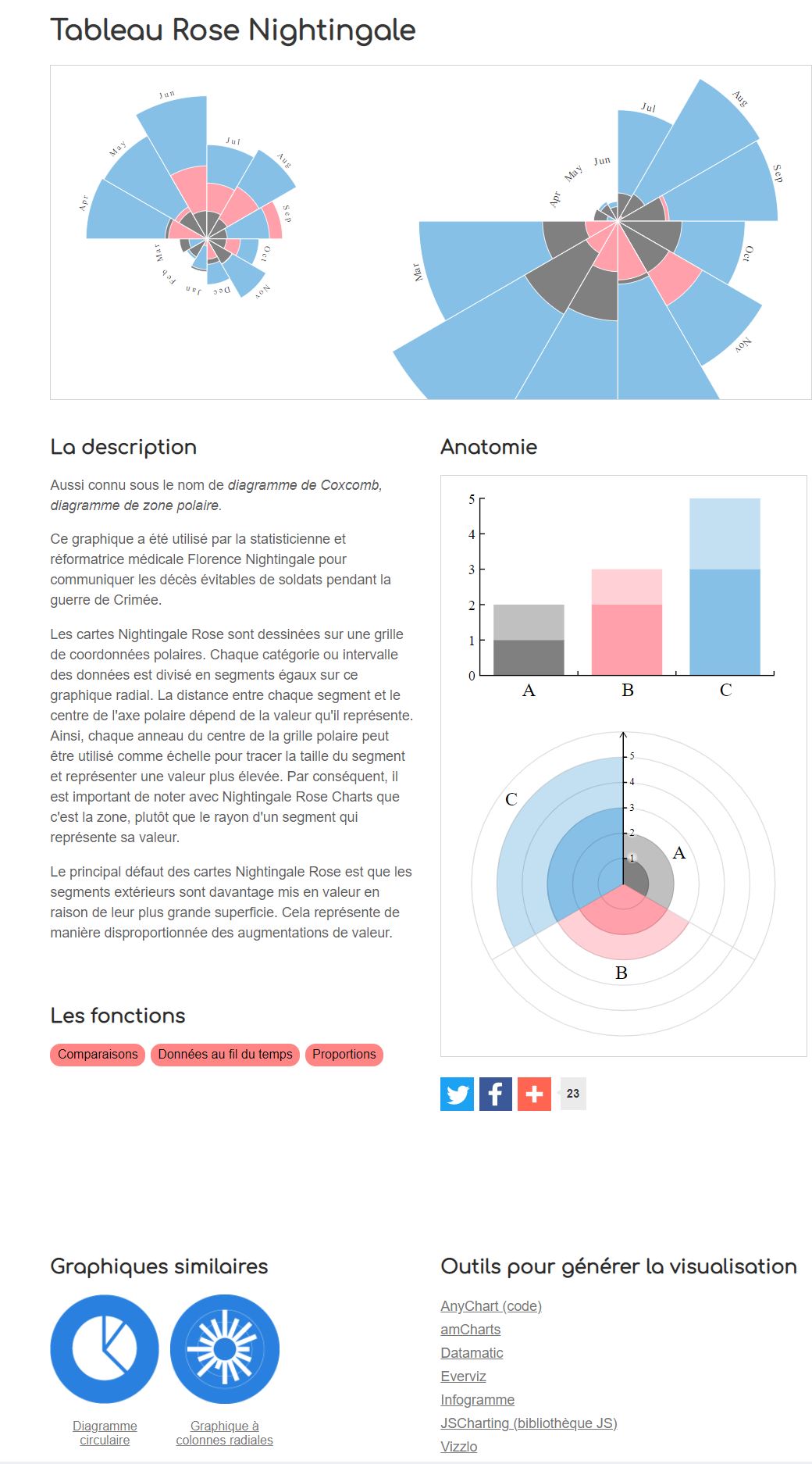
datavizcatalogue.com/
Avec des mots
Nuages de mots

Dans ce premier exemple, le texte intégral de Madame Bovary de Gustave Flaubert a été ajouté.
Cet exemple montre surtout l'indigence du traitement algorithmique.
Qu'est-ce qu'un mot ?
D'un point de vue informatique un mot est une chaîne de caractères situé entre deux blancs typographiques ou un blanc et un signe (, : ! etc.)
Outre les 2229 mots non dessinés c'est la seule occurrence qui est prise en compte comme critère d'affichage.
Le poids c'est le nombre !
Et plus un mot est présent, plus il est gros…
Dans ce hit parade des mots, seuls 2500 sur les 120 000 du texte sont retenus.
Ces mots sont rarement significatifs : "une" 860 occurrences, "cette" 211 occurrences etc., souvent polysémique, il n'y a aucune lemmatisafion déf., pas de liste de mots vides etc.
Deux traitements à partir de deux résumés, l'un court (764 c.) et l'autre long (22 000 c.)


pour un résultat qui n'est pas beaucoup plus convainquant
Le seul intérêt de ce type de nuage est surtout… esthétique.
… et bien moins que le résumé de Jean Rochefort…
MADAME BOVARY par Jean Rochefort
La vérité Jean Roch balance son premier feat avec les boloss des belles lettres !!!!! il
envoie sans aucune pression les bails littéraires façon gros moonwalk sur la piste avec
ce
classique posé : Madame Bovary, par Gustave Flaubert !
allez magueule fais bien nétour ça lache les pouces bleus et passe le kiss à la
fami
!!!!!
Text mining
Un véritable nuage de mots, autrement dit une liste de mots qui pourraient résumer un texte, nécessite des outils algorithmiques autrement plus performant. Ces outils sont souvent proposés en opensource.
Le text mining regroupe l’ensemble des techniques de data management et de data mining permettant le traitement des données particulières que sont les données textuelles. Par données textuelles, on entend par exemple les corpus de textes, les réponses aux questions ouvertes d’un questionnaire, les champs texte d’une application métier où des conseillers clientèle saisissent en temps réel les informations que leur donnent les clients, les mails, les posts sur les réseaux sociaux, les articles, les rapports…
Un des aspects centraux du text mining est de transformer ces données textuelles peu structurées – si ce n’est par la langue utilisée – en données exploitables par les algorithmes classiques de data mining. Il s’agit tout simplement de transformer un texte brut en tableau de données indispensable aux analystes chargés d’en dégager du sens. Il s’agit ensuite de déployer les méthodes statistiques les plus à même de répondre à une problématique donnée.
Google trend
Google trend est un outil issu de Google Labs permettant de connaître la fréquence à laquelle un terme a été tapé dans le moteur de recherche Google.
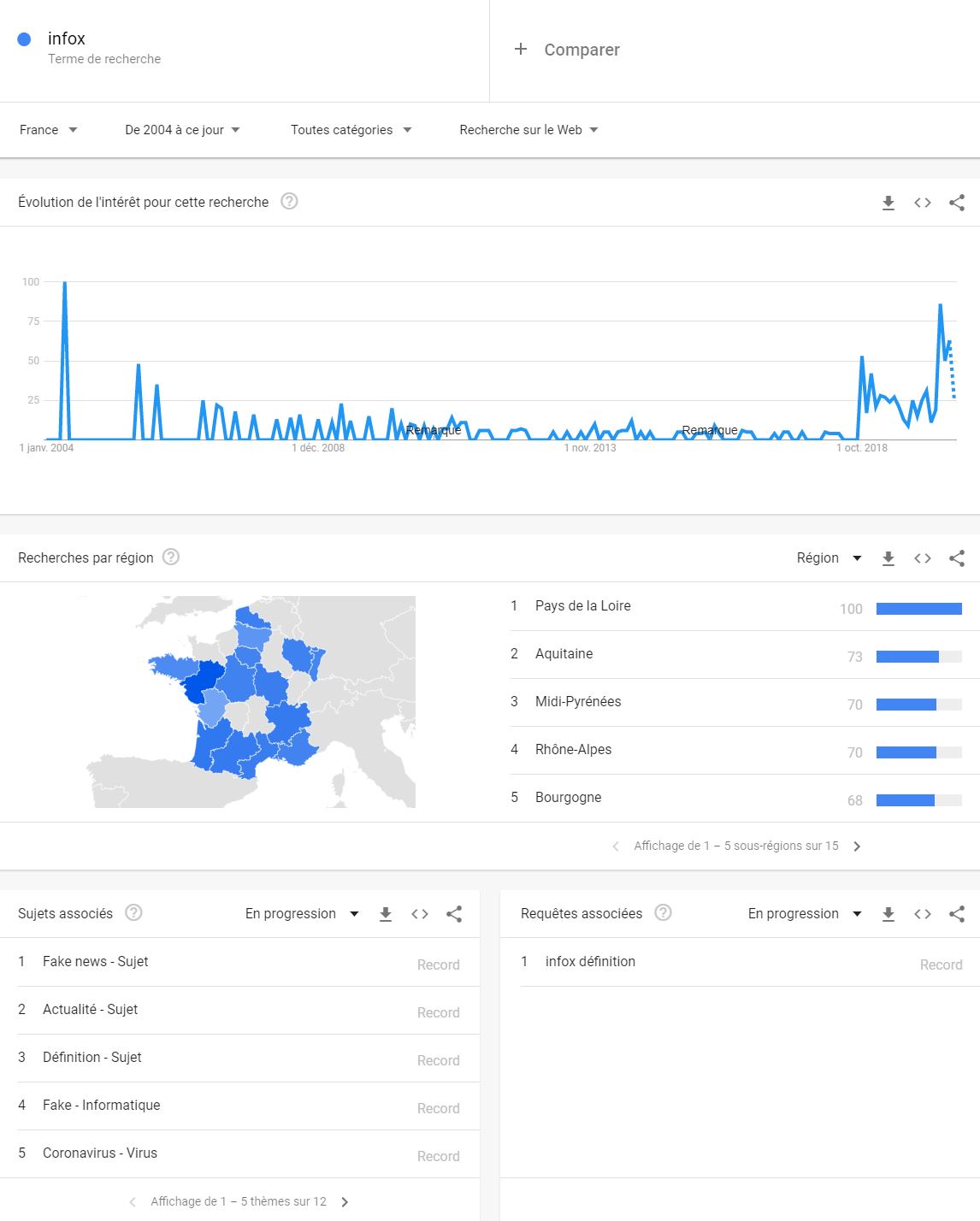
trends.google.fr/trends/
Openrefine
 Openrefine est un logiciel open
source
de nettoyage et de mise en forme de données. Openrefine a pour origine le logiciel Freebase
Gridworks dans les années 90, fut un temps racheté par Gooogle et bénéficies désormais de dons
pour
continuer son développement.
Openrefine est un logiciel open
source
de nettoyage et de mise en forme de données. Openrefine a pour origine le logiciel Freebase
Gridworks dans les années 90, fut un temps racheté par Gooogle et bénéficies désormais de dons
pour
continuer son développement.
A partir des "misérables" de Victor Hugo, un premier traitement a été effectué pour extraire les personnages et leurs liens (avec openRefine), mais un simple tableur peut également être utile.
77 personnages ont ainsi été retenus : Myrie, Napoléon, Mlle Baptistine, Mme Magloire, CountessDeLo, Geborand, Champtercier, Valjean, Marguerite…
Choix des indicateurs à représenter
Il est ensuite décidé d'analyser les relations qui existent entre les personnages. C'est ce que permet un logiciel du type Gephi, un logiciel libre d'analyse et de visualisation de réseaux.
Autre outil, directement en ligne, Table2net
Un graphique de données est ensuite exporté, puis affiché, ici avec d3js.
voir en pleine page
openrefine.org/
GATE, Tsouk
Dans le même style GATE est une solution open source à cycle de vie complet pour le traitement de
texte, l'analyse linguistique etc.
Il est livré avec un ensemble de modules d'extraction d'informations.
gate.ac.uk/
Tsouk est un site en ligne qui propose une visualisation de n'importe quelle page Web sous forme de graphe avec force Atlas 2. Il suffit de saisir l'adresse du site.
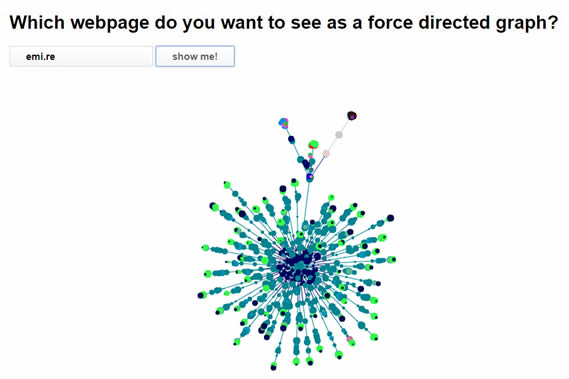
www.tsouk.com/html2graph/
Voyant tools
Voyant tools est pour le coup encore beaucoup plus complet puisqu'il propose d'analyser un contenu à partir d'un texte saisi ou d'une adresse.
Voyant Tools affiche ensuite une page de résultats sous forme de blocs
- Nuage de Tags. Une visualisation façon Wordclouds en forme de nuage de mots de votre texte. Vous pourrez choisir d’autres formes d’affichage du corpus des mots et si besoin en exclure certains.
- Lecteur. Ce bloc permet d’accéder au texte brut. On peut chercher un mot via une boîte de recherche. En cliquant sur un des mots du texte, on obtient un histogramme de fréquence sous le texte et le mot sélectionné devient le sujet d’analyse pour l’ensemble des blocs.
- Tendances. Outil puissant qui va permettre d’identifier les mots clés les plus utilisés, mais aussi les comparer entre eux et étudier leur proximité dans le texte.
- Résumé. Ce bloc résultat de l’analyse automatique de texte vous livre des infos statistiques sur le texte étudié : nombre de mots, nombre de documents, mots les plus fréquents, etc.
- Contextes. Ici vous trouverez lorsque vous sélectionnez un mot dans le lecteur, les phrases et les documents ou il est utilisé.
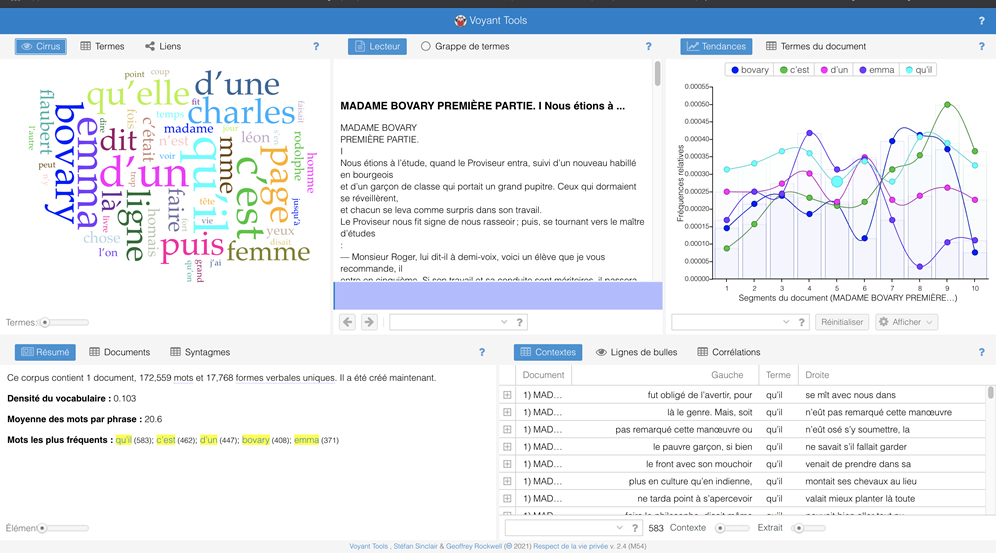
voyant-tools.org/
Carte mentale
Au début des années 70, Tony Buzan, un psychologue britannique, à la suite de ses recherches sur l’apprentissage et le cerveau humain, a donné naissance à une méthode d’organisation des idées, sous forme de dessin ou d’arborescence, la carte mentale (ou heuristique).
La carte mentale est est un graphique représentant des idées, des tâches, des mots, des concepts qui sont liés entre eux autour d’un sujet central. Il s’agit d’une représentation non-linéaire qui permet d’organiser ses idées de façon intuitive autour d’un noyau central.
Le point de départ est un mot, un concept, une idée, ensuite décliné en branches etc.
Si elle est de plus en plus souvent numérique, rien n'empêche de la réaliser d'abord au tableau (ou sur papier) pour ensuite formaliser les données.
Le plus souvent l'on commence par faire un remue-méninge (brainstorming) et choisir les mots-clés les plus pertinents sur le sujet.
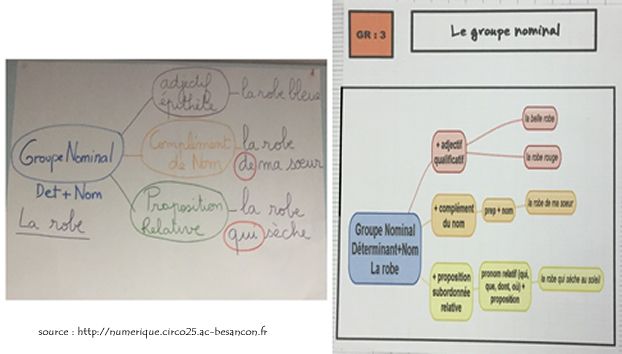
En tant qu'outil pour penser elle interviendrait plutôt en amont du processus (critique, sélections, choix des données etc.)
Avec des post-it
 Pour structurer ses idées de
façon naturelle et réaliser une carte mentale, on peut aussi utiliser des post-its.
Pour structurer ses idées de
façon naturelle et réaliser une carte mentale, on peut aussi utiliser des post-its.
1 post = 1 idée = 1 croquis avec un libellé qui décrit le croquis. Écrire en majuscule.
Au début tout est placé au mur en vrac, puis réorganisé, affiné…
Voir le déroulement sur https://openclassrooms.com/
Une carte mentale peut aussi devenir un moyen de communication, d'aide à la révision etc. et les plus belles le plus souvent réalisées à la main.
Sans le numérique
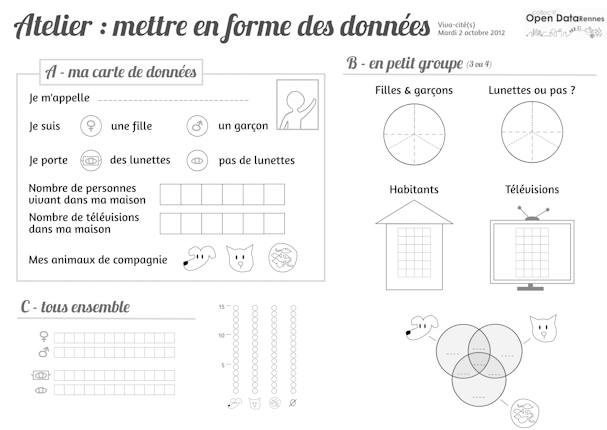 Le
collectif Open Data de Rennes organisait
le 2
octobre un atelier avec des enfants de CE2 et CM1, pendant lequel ils étaient sensibilisés à
l’art de récolter les données et de les mettre en forme de différentes façons : diagramme
circulaire, colonnes…
Le
collectif Open Data de Rennes organisait
le 2
octobre un atelier avec des enfants de CE2 et CM1, pendant lequel ils étaient sensibilisés à
l’art de récolter les données et de les mettre en forme de différentes façons : diagramme
circulaire, colonnes…
Le tout sans numérique.
Pour la récolte des données, les écoliers coloriaient des cases (Nombre de télé, d'animaux, genre etc.).
des Lego leur étaient ensuite remis pour réaliser les infographies.
www.warlogs.owni.fr/
Sociogramme
Le module sociogramme permet de visionner les relations au sein d'un groupe et ensuite d'en analyser les caractéristiques. Qui est qui ? Quelles sont ses interactions avec les autres membres du groupe ?
Il permet de générer un sociogramme, autrement dit un diagramme des liens sociaux qu'une personne possède comme celui-ci.
 Sociogramme
SociogrammeTrois réalisations en (presque) 3 clics
Les compétences de lecture des jeunes
Pour l'exemple ci-dessous nous allons réutiliser et présenter un jeu de
données
issu du site https://www.data.gouv.fr.
C'est un jeu de données sur les compétences en lecture des jeunes qui provient d'un
service public certifié.
Sur le site https://www.data.gouv.fr faire une recherche avec les mots clés "compétences lecture"
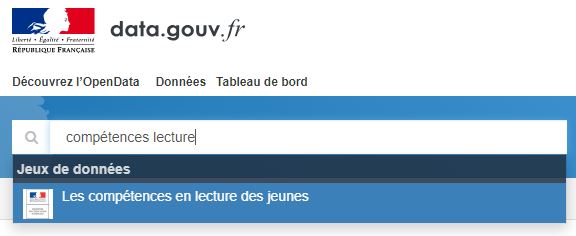
Télécharger la fiche "Les compétences en lecture des jeunes" (format xls).
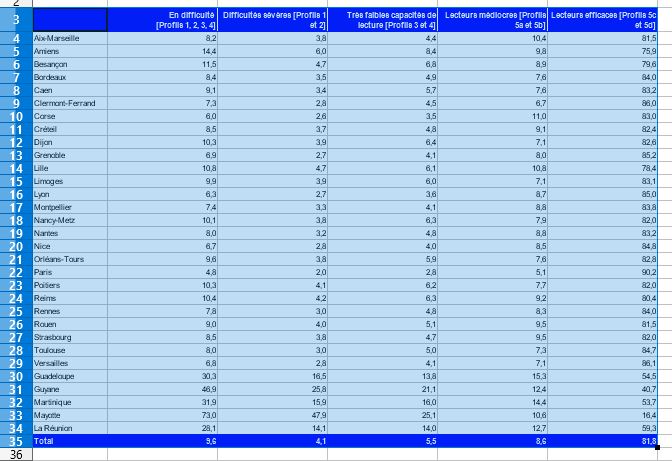
Copier les données de la feuille tab3 comme ci-dessous.
Si ce n'est déjà fait, créer un compte sur https://infogram.com/fr
D'autres sites existent et permettent de faire la même chose, citons donc
également
editor.highcharts.com/
qui a le bon goût de faire la même chose que le premier, mais sans limitations
de
plus en plus fortes.
Créer une nouvelle infographie (graphique seul) et lui donner un titre.
Coller les données et choisir une mise en forme.
Vous pouvez ensuite publier soit en mode image, soit en mode "embed".
Limites
Quelques remarques
Les données sont au format xls, propriétaire, peu adapté, limité à 65536 lignes jusqu’à
Excel
2007, désormais 1 048 576.
Ce qui n'est pas sans poser des problèmes. Voir par exemple
cet article du Point, plus de 15 000 cas de coronavirus n'ont pas été signalés
en
raison d'un problème de limite de tableau excel...
Infogram est limité en version gratuite et nécessite la création d'un compte.
Pour toutes ces raisons, l'on préfèrera par exemple l'éditeur Higharts ou Khartis avec des données au format csv.
Géolocaliser des points sur une carte
Il s'agit ici de saisir des données de géolocalisation dans un éditeur de texte puis de les importer sur une carte.
Avec un éditeur de texte, saisir les données, simplement séparées par des virgules : la première ligne contient la description de vos colonnes, chaque ligne correspond ensuite à une information.
Vous pouvez saisir ces données ou celles que vous voulez.
Enregistrer les données avec l'extension csv (fichier texte, séparateurs point
virgule).

 Sur
le site http://umap.openstreetmap.fr/,
Sur
le site http://umap.openstreetmap.fr/,
cliquer sur "importer des données",
saisir un titre puis cliquez sur "sélectionnez vos données".
Vous pouvez adapter votre carte, changer de fond, de type d'étiquette etc.
Un fois satisfait du résultat, cliquer sur enregistrer…

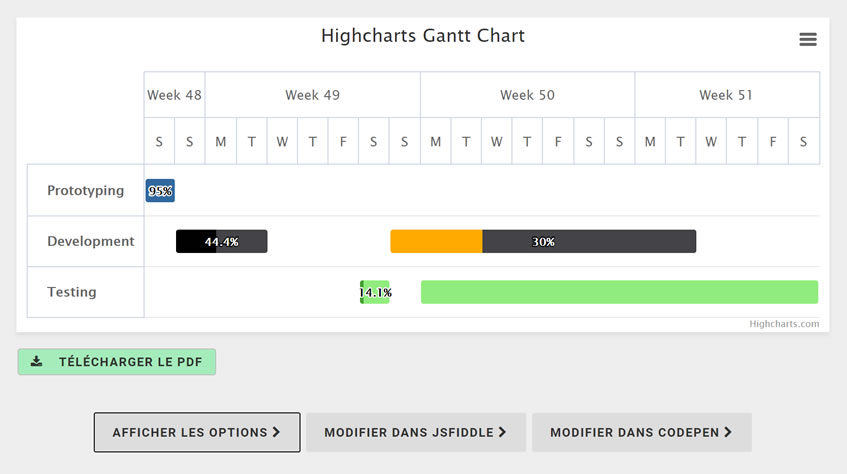
Diagramme de Gantt avec Highcharts
Il s'agit ici de réaliser un diagramme Gant en personnalisant un modèle proposé par Highcharts.
Highcharts propose une quantité impressionnante de graphiques, avec le code source. Ils
peuvent être modifiés en ligne, puis publiés où bon vous semble.
Pour cet exemple,
nous
allons modifier le code et le publier dans une page Web. Le diagramme pour être
téléchargé
en PDF.
La source proposée peut être visionnée ici et modifiée avec codepen en cliquant sur le bouton "MODIFIER DANS CODEPEN" ou avec JSFIDDLE si vous préférez.
Code complet
‹!DOCTYPE html›
‹html lang="fr"›
‹head›
‹meta charset="utf-8"›
‹title›Quel ratio admis/présents cette année ?‹/title›
‹script src="https://code.highcharts.com/gantt/highcharts-gantt.js"›‹/script›
‹script src="https://code.highcharts.com/gantt/modules/exporting.js"›‹/script›
‹style›
#container,
#button-container {
max-width: 800px;
margin: 1em auto;
}
#pdf {
border: 1px solid silver;
border-radius: 3px;
background: #a4edba;
padding: 0.5em 1em;
}
#pdf i {
margin-right: 1em;
}
‹/style›
‹/head›
‹body›
‹div id="container"›‹/div›
‹div id="button-container"›
‹button id="pdf"›
‹i class="fa fa-download"›‹/i› Download PDF
‹/button›
‹/div›
‹script›
Highcharts.ganttChart('container', {
title: {
text: 'Réaliser un diagramme de Gantt (rétroplanning)'
},
yAxis: {
uniqueNames: true
},
series: [{
name: 'Prépration de l\'oral',
data: [{
start: Date.UTC(2021, 9, 1),
end: Date.UTC(2021, 12, 1),
completed: 0.75,
name: 'Entraînement à l\'oral'
}, {
start: Date.UTC(2021, 12, 2),
end: Date.UTC(2022, 3, 1),
completed: 0.444,
name: 'Choix, traitement de la question'
}, {
start: Date.UTC(2022, 3, 1),
end: Date.UTC(2022, 6, 2),
completed: 0.141,
name: 'Entraînement'
}, {
start: Date.UTC(2022, 6, 3),
end: Date.UTC(2022, 6, 4),
completed: {
amount: 1,
fill: '#fa0'
},
name: 'Passage de l\'épreuve'
}]
}]
});
document.getElementById('pdf').addEventListener('click', function() {
Highcharts.charts[0].exportChart({
type: 'application/pdf'
});
});
‹/script›
‹/body›
‹/html›

Résultat
Les biais
Qui peuvent fausser la lecture…
Ce n'est pas parce que l'on représente des données, fussent-t-elles numériques, qu'elles sont
pout autant des représentations fiables.
Quelques exemples…
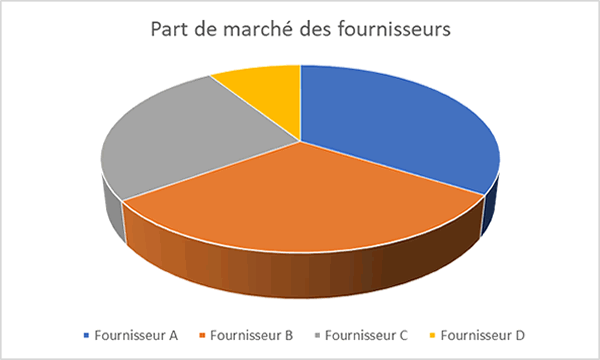
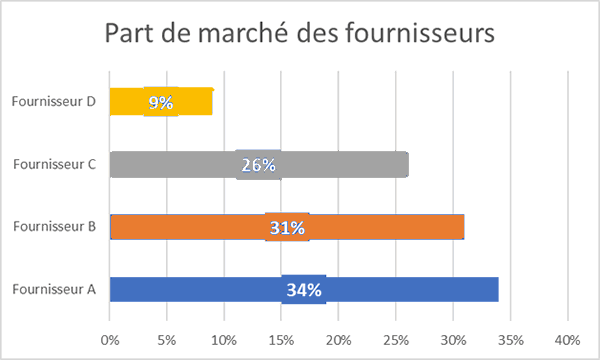
Les diagrammes à secteurs ne sont pas de bonnes représentations des données. Ils ne permettent pas de déterminer facilement d'attribuer une valeur numérique à un élément dans un espace en deux dimensions.
Lire des valeurs en 3D
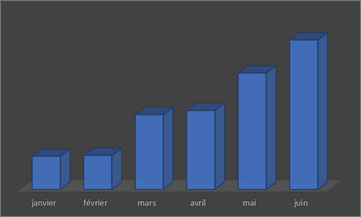
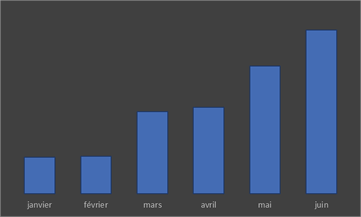
La 3D ne facilite que rarement la lecture des données.
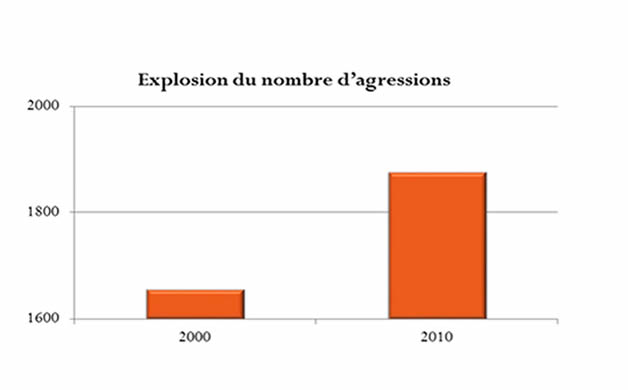
Augmentation importante ou pas ?
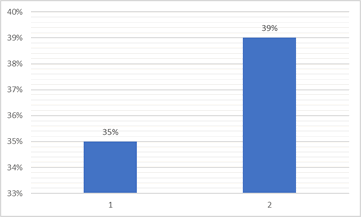
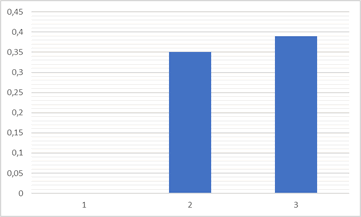
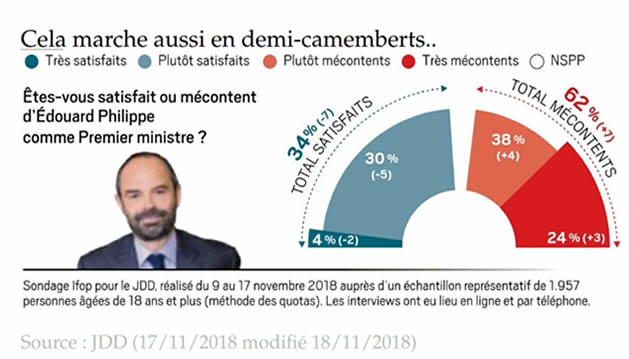
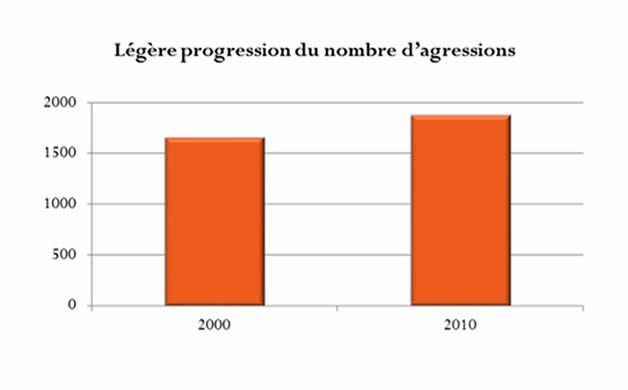
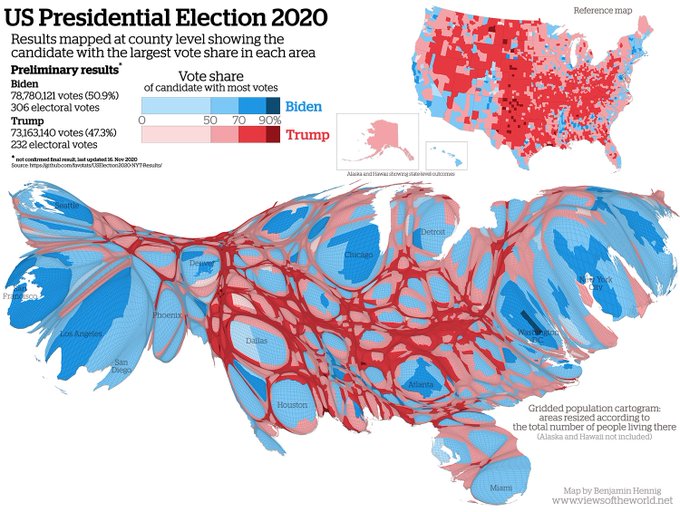
Par électeur ou par comté ?
Try To Impeach This by Karim Douieb
The #dataviz created by Brussels-based data scientist Karim Douieb made the buzz after the 2020 US presidential elections. In this data visualization Karim shows that "land doesn't vote". It's the people who vote and in spite of an abundance of red, the vote turned out to be "blue".
Analyser et discuter les choix cartographiques, choisir son niveau d'analyse, croiser les résultats avec d'autres données, interroger les nouvelles formes de représentation cartographique
cartonumerique.blogspot.com/n
Diagrammes à bâton
La base des diagrammes à bâton n'est pas la même ce qui fausse la lecture.
… ou l'améliorer
L'ajout d'une caractéristique préattentive
facilite grandement la lecture
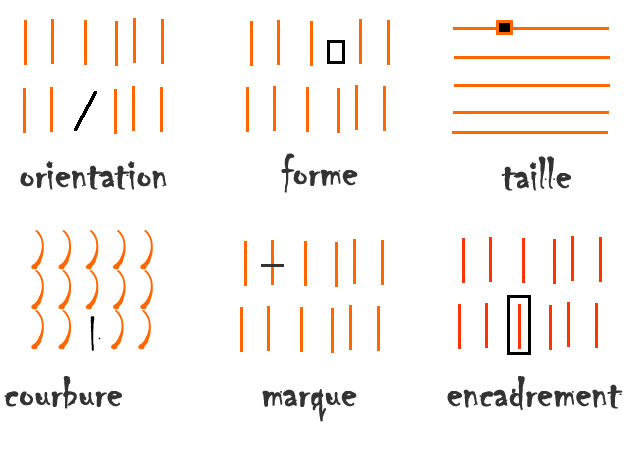
Ces caractéristiques de lecture pré attentives
peuvent être utilisées
pour créer une hiérarchie visuelle

Data visualisation dans les médias
L'usage de la data visualisation dans les médias
Pour ce huitième numéro, dans le cadre du nouveau thème de la Semaine de la presse et des médias dans l'École® "L'information sans frontières ?", nous nous sommes intéressés à la data visualisation. Quels sont les avantages et les inconvénients de ces infographies ? Dans quel but sont-elles utilisées ? C’est le thème de ce nouveau numéro de Déclic’Critique tourné dans une classe de seconde du lycée Jean Renou de La Réole (Académie de Bordeaux)
Les faux !
Les biais ne sont pas toujours volontaires, mais que dire des faux ?
Trouvez-l'erreur !
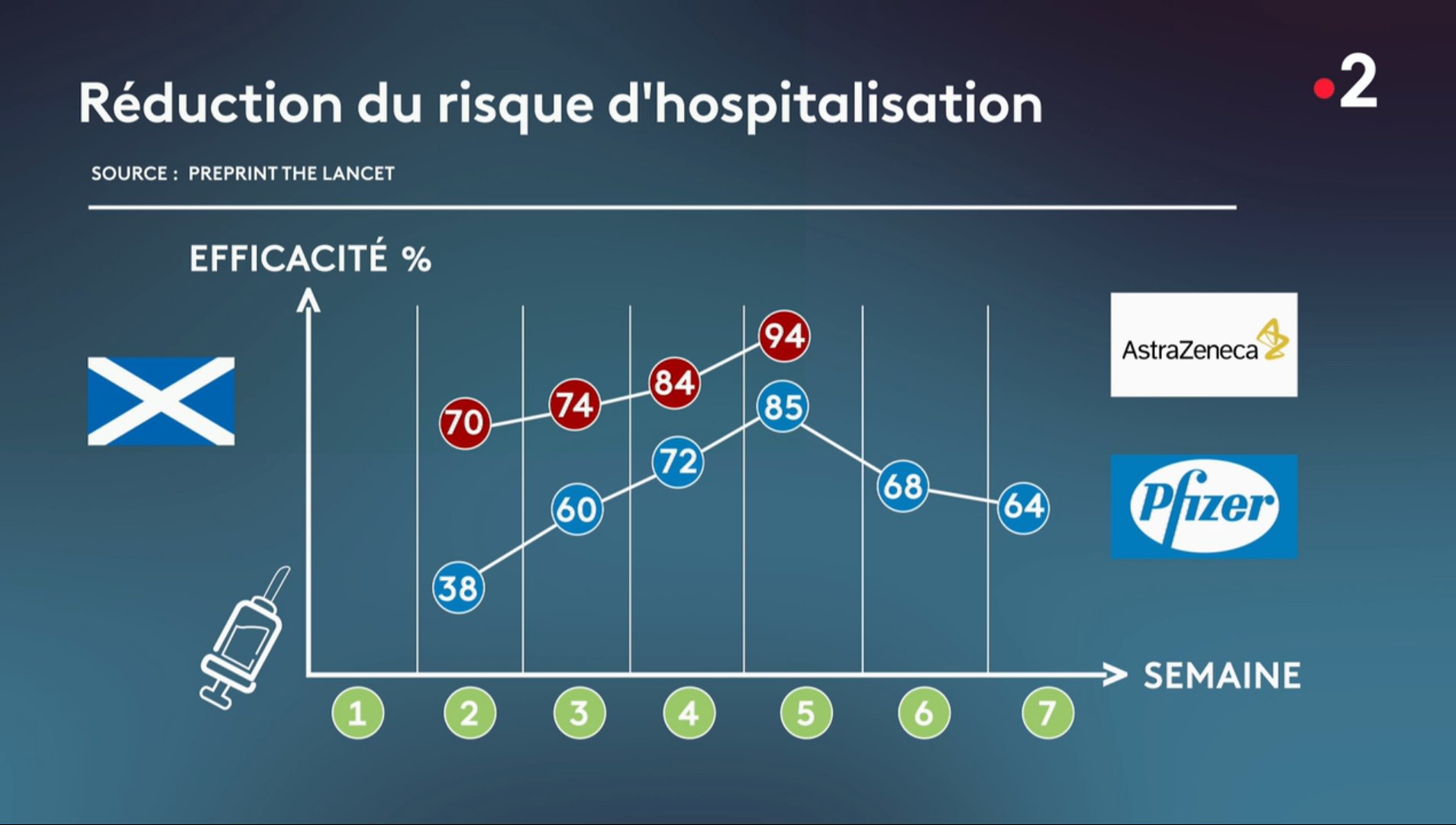
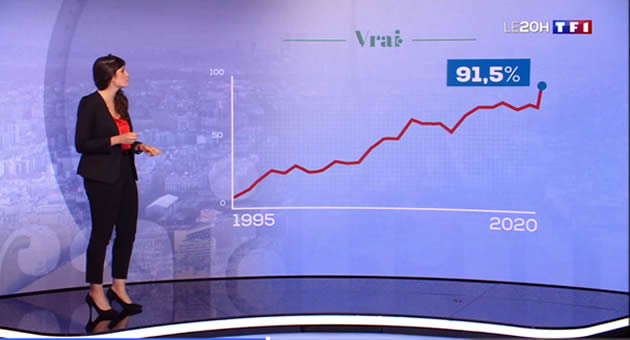
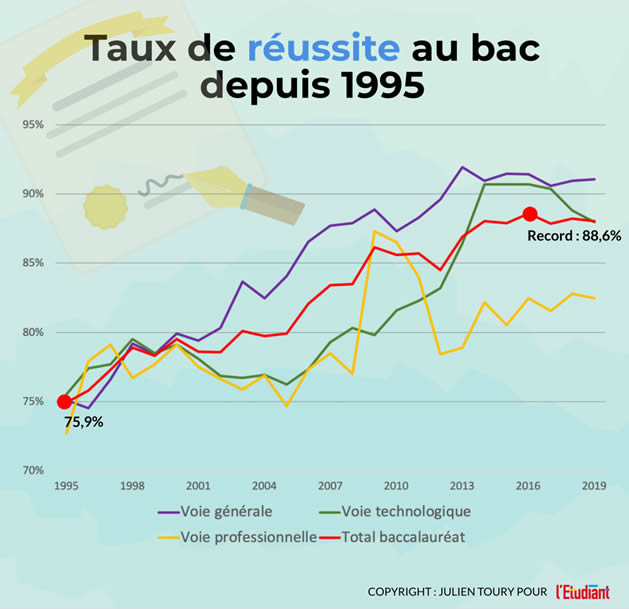
Faire mentir les chiffres
Dans ce nouvel épisode de « La Collab' de l'info », Johanna Ghiglia, journaliste sur France Info, et Lê Nguyen Hoang, mathématicien connu pour son travail de vulgarisation grâce à sa chaîne YouTube Science4All, échangent sur les chiffres.
www.lumni.fr/
www.edrawsoft.com/
numerique.circo25.ac-besancon.fr/
www.freeplane.org/
www.scoop.it/t/classemapping
Les étapes d'une data visualisation ?
Compiler
 La
première étape consiste à trouver et
compiler les données. De nombreux fournisseurs en proposent.
La
première étape consiste à trouver et
compiler les données. De nombreux fournisseurs en proposent.
Cette compilation se fait soit à l'aune d'une question à laquelle vous devez apporter des données, soit un ensemble de données a besoin d’un questionnement pour en extirper du sens.
L’étape de compilation est la plus importante puisqu’il est possible de revenir à cette étape plusieurs fois dans le processus et parce que les autres étapes ne sont pas réalisables sans celle-ci.
De nombreux services officiels mettent à disposition leurs données. C'est souvent même une obligation légale (voir Loi sur l'économie numérique).
La Bibliothèque Nationale de France met son catalogue à disposition, plus de
880 000
auteurs, 185 000 œuvres, 56 000 spectacles…
Vous pouvez ainsi retrouver la biographie de quasiment n'importe quel auteur.
Exemple, celle de Allessandro Volta.
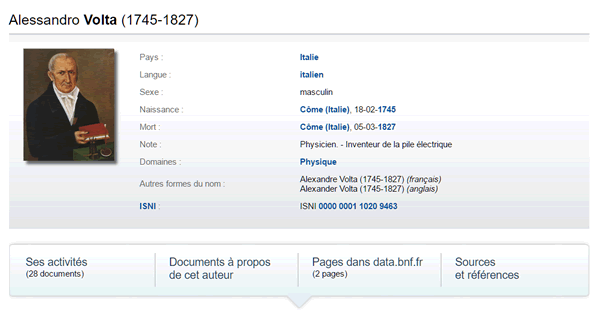
data.bnf.fr/
Et comme la BNF propose une API pour accéder à ses données, il est facile d'implémenter un formulaire d'interrogation de la base.
Vous pouvez la tester ci-dessous avec un auteur (trouver la référence d'un auteur)
Fournisseurs de données
 DataFrance
DataFrance
Un peu plus de 50 jeux de données sur une carte interactive. Éducation, économie,
transports
publics, etc.
Plus de 36 000 fiches dédiées à chaque commune, ce qui fait de DataFrance un outil
plus
particulièrement adapté à la recherche immobilière pour par exemple mieux connaître
l’environnement d’un bien.
datafrance.info/
 data.gouv
data.gouv
Plateforme ouverte des données publiques françaises, l'offre la plus vaste, avec plus de
36 000 jeux de données mi 2019. Classement par thèmes, moteur de recherche, possibilité
de
contribuer…
www.data.gouv.fr/fr/
![]() Opendata.europa
Opendata.europa
Plus de 8 000 ensembles de données disponibles essentiellement fournis par Eurostat
et
diverses institutions, agences et organes de l’UE. Possibilité d'accéder au portail des
données
ouvertes de l'UE est d'utiliser l'API REST.
open-data.europa.eu/fr/data"
 OpenParis
OpenParis
Les villes s'y mettent également. L'on peut citer par exemple celle de Paris et plus de
250
jeux de données en ligne.
opendata.paris.fr/page/home/
Si les administrations commencent à fournir des données, on est cependant très loin du compte.
Les jeux de données eux-mêmes nécessitent souvent beaucoup de nettoyage pour être
exploitables.
Ils sont même souvent dans des formats propriétaires (type xls), avec des saisies
non
normées, des données manquantes, des adresses fausses etc.
Peut (beaucoup) mieux faire !
Signalons également pour des données à granularité mondiale :
Méthodes non "orthodoxes"
Web scraping
Lorsque les sites officiels ne fournissent pas les données, ou qu'elles ne sont pas envoyées sur des sites dédiés, il y a aussi la méthode du web scraping, autrement dit une technique d'extraction du contenu de sites Web, via un script ou un programme.
Cette pratique n'a pas très bonne presse et peut être assimilée à un pillage.
Google Actualités, en agrégeant sans autorisation préalable les manchettes d'autres sites, est considéré par certains comme faisant du Web scraping.
Mais elle peut aussi être utilisée pour accéder aux données diffusées dont l'accès n'a pas été facilité, y compris quelquefois pour des données censées être publiques.
Lanceurs d'alerte
De nombreuses données proviennent également de lanceurs d'alertes et La RTBF, Le Monde, Le Soir et La Libre Belgique mettent en ligne « source sûre », la première plateforme francophone internationale destinée aux lanceurs d'alerte.
www.sourcesure.eu/page/home/
Citons également FrenchLeaks, un site dédié à la diffusion de documents d’intérêt public concernant notamment la France et l’Europe. Edité par le journal d’information en ligne Mediapart
https://www.frenchleaks.fr/
 Imprimées sur des feuilles A4, les données
diffusées par E. Snowden et récupérées sur clé USB représenteraient 18 km de haut.
Imprimées sur des feuilles A4, les données
diffusées par E. Snowden et récupérées sur clé USB représenteraient 18 km de haut.
Nettoyer
 Toutes les données ne sont pas structurées
ou même semi structurées (fournies avec des metadonnées). Pour être exploitables elles doivent
alors être nettoyées des valeurs inutiles.
Toutes les données ne sont pas structurées
ou même semi structurées (fournies avec des metadonnées). Pour être exploitables elles doivent
alors être nettoyées des valeurs inutiles.
Le nettoyage des données permet de supprimer les erreurs, celles inutiles, les trier ou convertir les données dans un format exploitable.
Une très bonne connaissance des tableurs ou des outils plus spécialisées du type ) (voir plus loin) sont ici indispensables.
C'est une opération pouvant être longue voir très longue, puisqu'il faudra, lemmatiser,
élaguer,
corriger, trier, fusionner ou scinder etc.
Bref, avant même de vouloir en faire ressortir du sens un gros travail préparatoire est
le
plus souvent nécessaire.
Contextualiser
 Les
données sont-elles fiables ? Qui
les
produit ? Quand ? Dans quel but ?
Les
données sont-elles fiables ? Qui
les
produit ? Quand ? Dans quel but ?
Ce sont des questions de bases que tout journaliste et tout data annaliste se pose et qui restent d'actualité pour les données.
Le contexte peut influencer la compréhension de certaines données. Avoir une question et une idée claire dès le début de l’ensemble du processus facilite la démarche.
Combiner
 Plusieurs données peuvent créer une
seule
information, c’est pourquoi il est important de combiner les données.
Plusieurs données peuvent créer une
seule
information, c’est pourquoi il est important de combiner les données.
La multiplication des sources impliquent aussi une combinaison des données et permettent de vérifier leur véracité. D’autres pistes de travail peuvent également être explorées.
Communiquer
 La
dernière étape à effectuer est la
visualisation des résultats avant leur publication.
La
dernière étape à effectuer est la
visualisation des résultats avant leur publication.
Du graphique isolé au dashboard interactif les possibilités sont nombreuses.
 Datajournalisme
Datajournalisme
Exemple décortiqué : 560 000 mots clés
 Il y a près de 10 ans, l'auteur de
cette
page proposait un module, désormais plus actif, mais qui générait plus de 100 000
requêtes par an. Il permettait de suggérer un indice Dewey à partir de mots ou de
chiffres.
Il y a près de 10 ans, l'auteur de
cette
page proposait un module, désormais plus actif, mais qui générait plus de 100 000
requêtes par an. Il permettait de suggérer un indice Dewey à partir de mots ou de
chiffres.
Dans cet exemple nous allons tenter de visualiser quelques éléments à partir des 5 dernières années de saisies, 560 000 requêtes.
Extraction du fichier, nettoyage
Dans un premier temps, les 560 000 requêtes sont insérées dans une table excel pour un premier niveau de tri.
Elles sont ensuite exportées au format csv pour être exploitées via divers outils.
Le tout est présenté sous forme de dashboard.